- 面对问题束手无策
- 面对“系统”、“底层”发怵
- 遇到根源复杂的性能问题既不懂怎么去分析,也不能抽丝剥茧的找到瓶颈
- 随遇而安,认为遇到问题上网查就行了。有可能解决问题,但是懒得研究为何有效
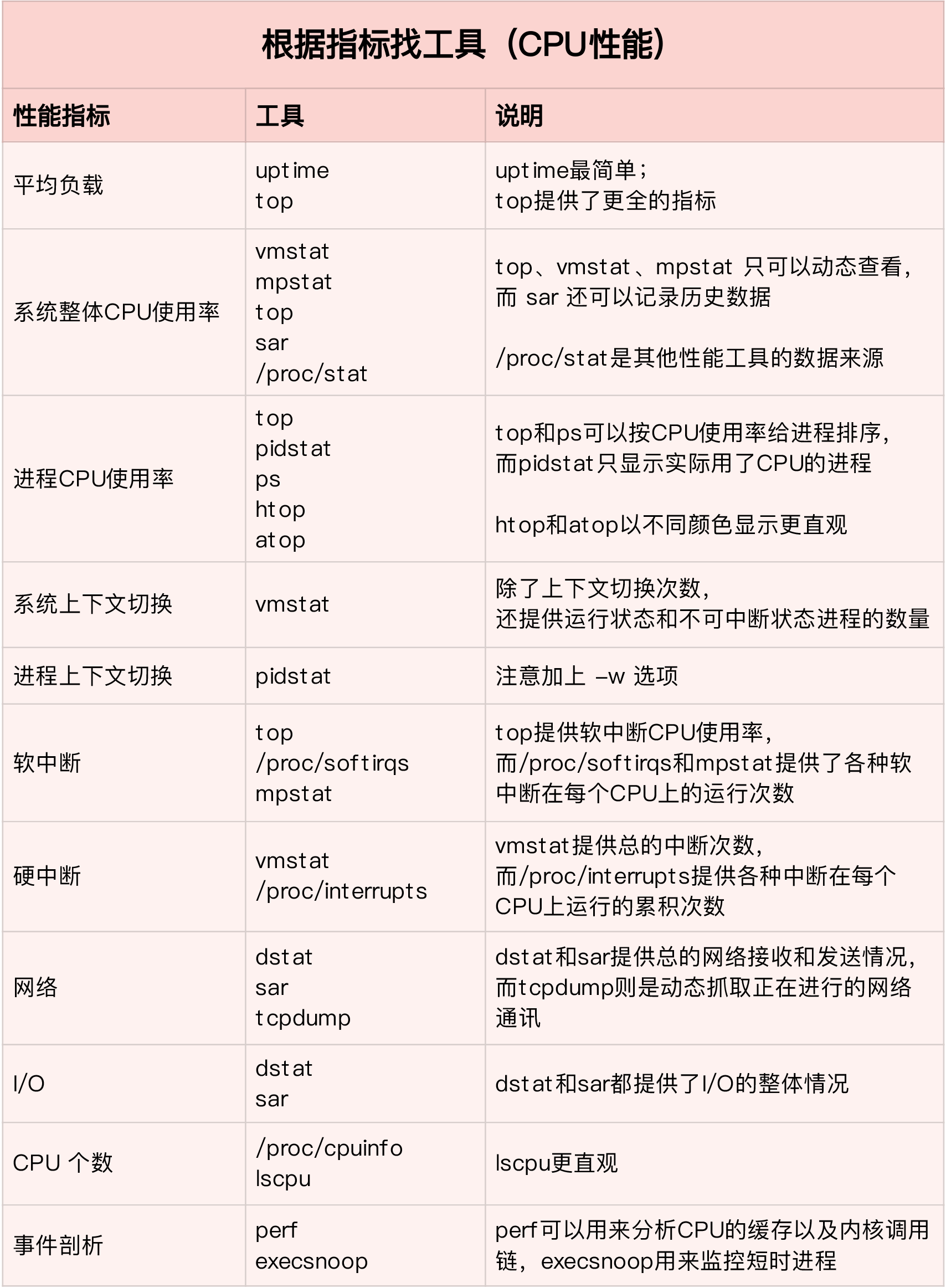
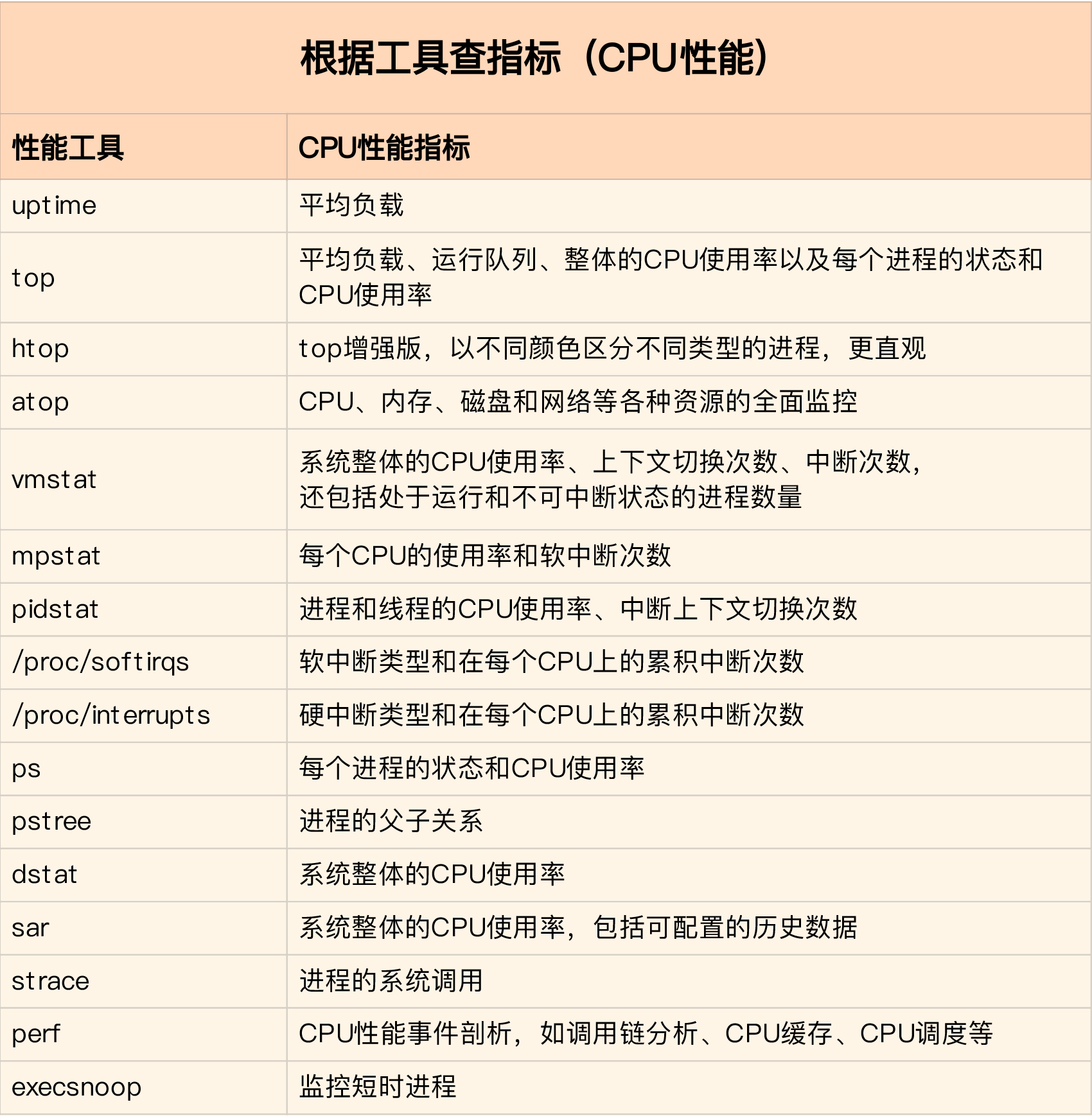
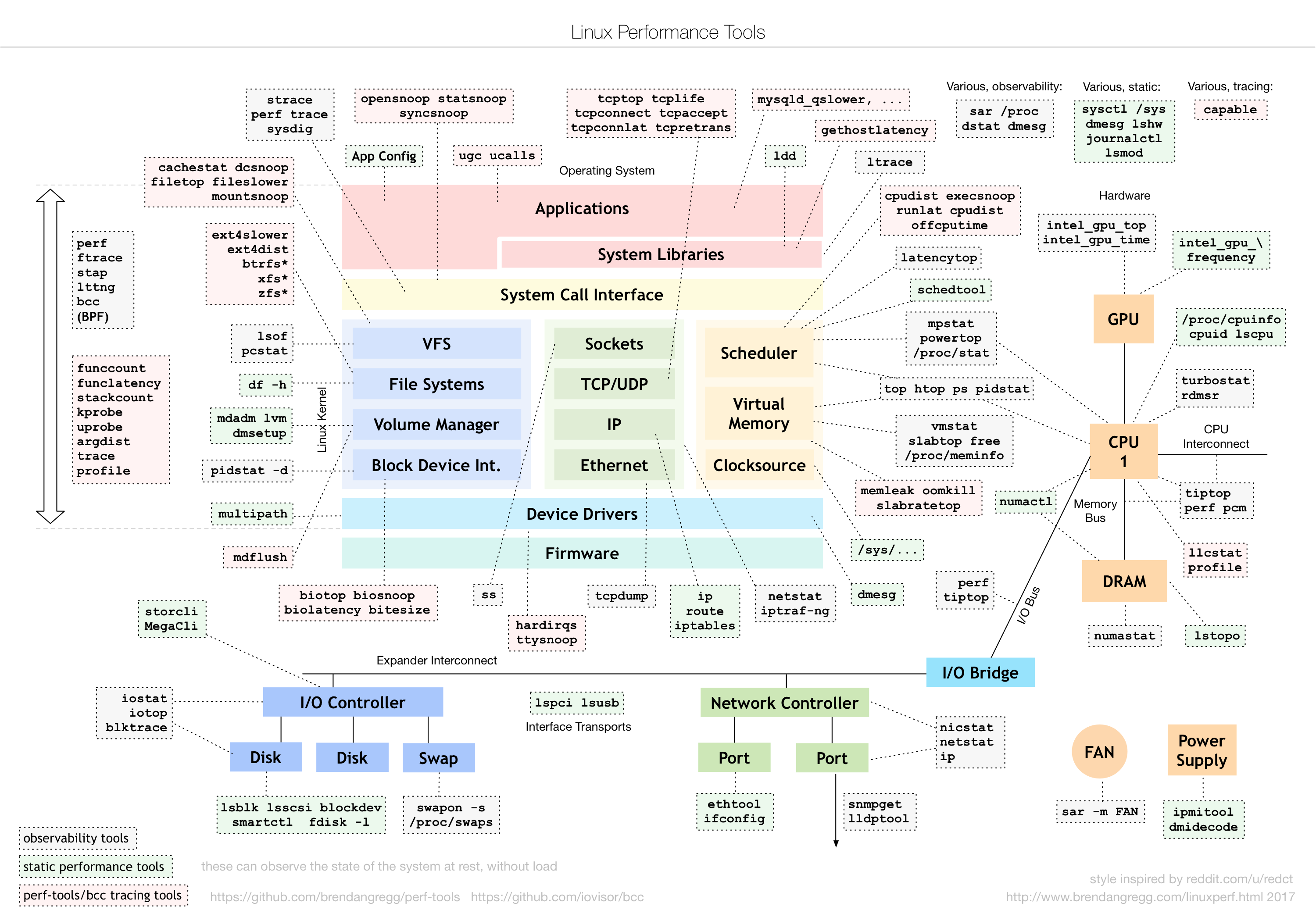
性能和性能分析
关于性能,我们首先想到的就是高并发、响应快。这两个词对应着性能优化的两个核心指标“吞吐”和“延时”。而这两个指标是
从应用负载的角度来考察性能。我们知道,随着应用负载的增加,系统资源的使用也会升高,甚至达到极限。而性能的本质就
是系统资源达到瓶颈,无法支撑更多的请求。
性能分析就是为了找出应用或者系统的瓶颈,并设法去避免或者缓解它们
,从高更高效的利用系统资源处理更多的请求。这通常包含了以下几个步骤:
- 选择指标评估应用程序和系统的性能
- 为应用程序和系统设置性能目标
- 进行性能基准测试
- 性能分析定位瓶颈
- 优化系统和应用程序
- 性能监控和告警
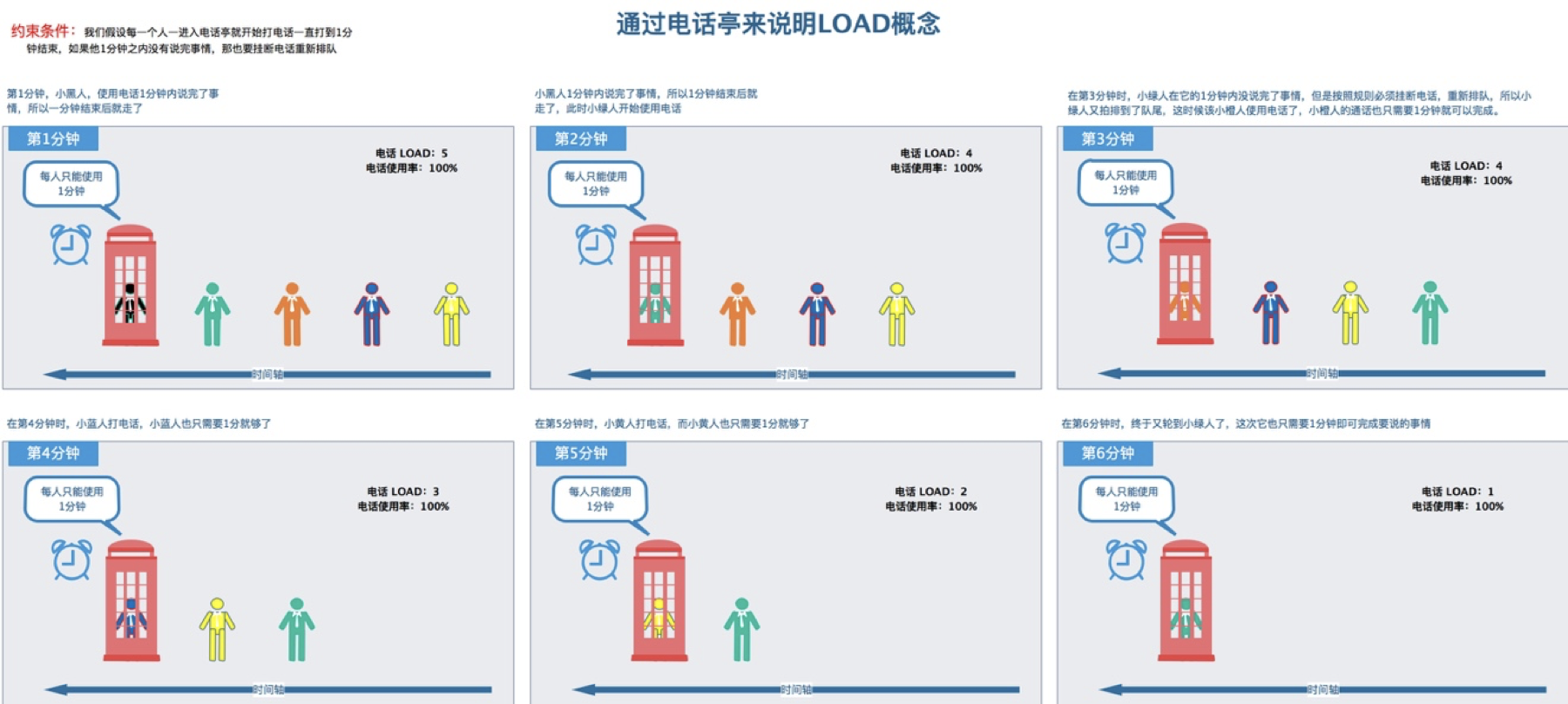
理解平均负载
当发现系统变慢的时候,我们通常做的第一件事就是执行top或者uptime来观察系统负载情况。
1
2
|
[root@test-monitor-alert-1 ~]# uptime
10:26:33 up 26 days, 17:10, 2 users, load average: 0.02, 0.04, 0.05
|
1
2
3
4
|
10:26:33 // 当前时间
up 26 days // 系统运行时间
2 users // 正在登陆用户
load average: 0.02, 0.04, 0.05 // 依次则是过去 1 分钟、5 分钟、15 分钟的平均负载
|
理解平均负载之前我们先了解以下两种状态
- 可运行状态: 所谓可运行状态的进程,是指正在使用CPU或者正在等待CPU的进程,也就是我们常用ps命令看到的,处于R状态(Running 或 Runnable)的进程。
- 不可中断状态: 不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的I/O响应,也就是我们在ps命令中看到的D状态(Uninterruptible Sleep,也称为 Disk Sleep)的进程。
平均负载实际上就是平均活跃进程数,直观上的理解就是单位时间内的活跃进程数,但它实际上是活跃进程数的指数衰减平均值。这个“指数衰减平均”的详细含义不用计较,这只是系统的一种更快速的计算方式,你把它直接当成活跃进程数的平均值也没问题。
举个例子,当平均负载为2时意味着什么:
- 在只有2个CPU的系统上,意味着所有CPU刚好被完全占用
- 在只有4个CPU的系统上,意味着CPU有50%的空闲
- 在只有1个CPU的系统上,意味着有一半的进程竞争不到CPU
平均负载多少合理
回答这个问题之前我们需要知道系统有几个CPU,可以通过top或者从文件/proc/cpuinfi中读取
1
2
|
[root@test-monitor-alert-1 ~]# grep 'model name' /proc/cpuinfo | wc -l
4
|
有了CPU个数就可以判断出当平均负载比CPU个数还打当时候,系统已经出现了过载。那么平均负载的三个数值理解如下:
- 如果1、5、15的三个数值基本相同,或者相差不大,那么说明系统负载很平稳
- 如果1的值远小于15分钟的值,说明系统最近1分钟负载在减少,过去15分钟内负载很高,反之同理
平均负载高于CPU数量70%当时候就需要排查负载高的原因
平均负载与CPU使用率
在实际工作中我们经常把平均负载与CPU使用率混淆,平均负载是指单位时间内处于可运行状态和不可中断状态的进程数。所以他不仅包括了正在使用的CPU进程,还
包括等待CPU和等待I/O的进程。
而CPU使用率是单位时间内CPU繁忙情况的统计,跟平均负载并不一定完全对应。
- CPU密集型进程,使用大量CPU会导致负载升高,此时两者一致
- I/O密集型进程,等待I/O会导致平均负载升高,但CPU使用率不一定很高
- 大量等待CPU的进程调度也会导致平均负载升高,此时CPU使用率也会比较高
 cxsd
cxsd

场景分析
准备
- Linux
- stress Linux系统压力测试工具
- sysstat 包含了常用的Linux性能工具,用来监控和分析系统性能。mpstat用来实时查看每个CPU的性能指标,以及所有CPU的平均指标。pidstat是一个进程性能分析工具,用来实时查看进程的CPU、内存、I/O以及上下文切换等性能指标
CPU密集型进程
1
2
3
|
# 测试之前的数据
[root@test-monitor-alert-1 ~]# uptime
19:59:55 up 27 days, 2:43, 7 users, load average: 0.05, 0.07, 0.11
|
1
2
3
|
# 模拟两个CPU使用率100%
[root@test-monitor-alert-1 ~]# stress --cpu 2 --timeout 600
stress: info: [12880] dispatching hogs: 2 cpu, 0 io, 0 vm, 0 hdd
|
1
2
3
4
5
|
# uptime查看平均负载变化情况
[root@test-monitor-alert-1 ~]# watch -d uptime
Every 2.0s: uptime Tue Nov 24 20:03:27 2020
20:03:27 up 27 days, 2:47, 7 users, load average: 1.98, 0.97, 0.45
|
1
2
3
4
5
6
7
8
9
10
11
|
# mpstat查看CPU使用情况 -P ALL 表示监控所有CPU,后面数字5表示间隔5秒后输出一组数据
[root@test-monitor-alert-1 sysstat-11.6.5]# ./mpstat -P ALL 5
Linux 3.10.0-1127.19.1.el7.x86_64 (test-monitor-alert-1) 11/25/2020 _x86_64_ (4 CPU)
09:26:34 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
09:26:39 AM all 0.35 0.00 2.17 81.48 0.00 0.00 0.00 0.00 0.00 15.99
09:26:39 AM 0 0.40 0.00 1.82 57.17 0.00 0.00 0.00 0.00 0.00 40.61
09:26:39 AM 1 0.40 0.00 4.23 83.30 0.00 0.00 0.00 0.00 0.00 12.07
09:26:39 AM 2 0.40 0.00 1.01 90.30 0.00 0.00 0.00 0.00 0.00 8.28
09:26:39 AM 3 0.20 0.00 1.41 95.35 0.00 0.00 0.00 0.00 0.00 3.03
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
# 到底是哪个进程导致了 CPU 使用率为 100% 呢?你可以使用 pidstat 来查询:
# 间隔5秒后输出一组数据
[root@test-monitor-farseer-1 sysstat-11.6.5]# dstat --top-io -d --top-bio -l
----most-expensive---- -dsk/total- ----most-expensive---- ---load-avg---
i/o process | read writ| block i/o process | 1m 5m 15m
docker-cont4376B 1002k| 16k 99k|systemd 9524B 58k|0.18 0.70 0.59
prometheus 11k 11k| 0 1196k|prometheus 0 8192B|0.18 0.70 0.59
barad_agent 42k 10k|8192B 0 |barad_agent 0 12k|0.16 0.69 0.59
process-exp1462k 16k| 24k 320k|systemd-jou 0 260k|0.16 0.69 0.59
stress-ng 0 744M|4792k 114M|stress-ng 0 744M|0.16 0.69 0.59
stress-ng 1024M 281M|8192B 106M|stress-ng 0 280M|0.16 0.69 0.59
barad_agent 23k 2367B|8192B 114M|prometheus 0 4096B|0.16 0.69 0.59
YDService 9524B 1447B| 12k 111M|jbd2/vda1-8 0 28k|0.63 0.78 0.62
systemd-jou 31k 0 | 12k 96M|systemd-jou 0 172k|0.63 0.78 0.62
barad_agent4010B 2535B| 12k 111M|barad_agent 0 4096B|0.63 0.78 0.62
YDService 6380B 0 |4096B 115M|jbd2/vda1-8 0 16k|0.63 0.78 0.62
prometheus 11k 11k| 20k 104M|YDService 12k 0 |0.63 0.78 0.62
barad_agent 42k 10k|8192B 107M|YDService 12k 0 |0.90 0.83 0.64
stress-ng 1024M 1024M| 24k 108M|stress-ng 0 1024M|0.90 0.83 0.64
YDService 4971B 164B|8192B 104M|prometheus 0 4096B|0.90 0.83 0.64
systemd-jou6478B 0 |4096B 107M|systemd-jou 0 56k|0.90 0.83 0.64
node_export 44k 11k| 16k 108M|jbd2/vda1-8 0 136k|0.90 0.83 0.64
# pidsta版本问题,抓不出io wait
[root@test-monitor-farseer-1 sysstat-11.6.5]# ./pidstat -u 5 1
Linux 3.10.0-1127.19.1.el7.x86_64 (test-monitor-farseer-1) 12/01/2020 _x86_64_ (4 CPU)
03:42:58 PM UID PID %usr %system %guest %wait %CPU CPU Command
03:43:03 PM 0 9 0.00 0.20 0.00 0.20 0.20 1 rcu_sched
03:43:03 PM 0 14 0.00 0.20 0.00 0.00 0.20 1 ksoftirqd/1
03:43:03 PM 0 24 0.00 0.20 0.00 0.00 0.20 3 ksoftirqd/3
03:43:03 PM 0 184 0.00 0.20 0.00 0.00 0.20 1 kauditd
03:43:03 PM 0 1347 0.00 0.20 0.00 0.00 0.20 1 dockerd
03:43:03 PM 1000 2066 1.20 1.20 0.00 0.00 2.40 0 java
03:43:03 PM 65534 2525 0.20 0.00 0.00 0.00 0.20 1 prometheus
03:43:03 PM 0 4926 0.20 0.00 0.00 0.00 0.20 2 docker-proxy
03:43:03 PM 0 4950 0.00 0.40 0.00 0.00 0.40 3 etcd
03:43:03 PM 0 5317 0.00 0.20 0.00 0.20 0.20 1 fs-monitor
03:43:03 PM 0 9761 100.00 0.00 0.00 0.00 100.00 0 stress
03:43:03 PM 0 9762 99.80 0.00 0.00 0.00 99.80 2 stress
03:43:03 PM 0 9780 0.00 0.20 0.00 0.00 0.20 3 pidstat
03:43:03 PM 0 26236 0.20 0.20 0.00 0.00 0.40 0 barad_agent
03:43:03 PM 0 28925 0.00 0.40 0.00 0.00 0.40 1 YDService
03:43:03 PM 0 28985 0.20 0.20 0.00 0.00 0.40 3 YDEdr
# 从这里可以明显看到,stress 进程的 CPU 使用率为 100%。
|
IO密集型
1
2
3
|
# 测试之前的数据
[root@test-monitor-alert-1 ~]# uptime
09:25:35 up 27 days, 3:21, 8 users, load average: 0.35, 0.94, 0.60
|
1
2
3
4
|
# 模拟IO打满
[root@test-monitor-alert-1 ~]# stress-ng -i 1 --hdd 1 --timeout 600
stress-ng: info: [4710] dispatching hogs: 1 hdd, 1 io
|
1
2
3
4
5
6
|
# uptime查看平均负载变化情况
[root@test-monitor-alert-1 ~]# watch -d uptime
Every 2.0s: uptime Wed Nov 25 09:25:38 2020
09:25:38 up 27 days, 16:09, 4 users, load average: 2.49, 0.69, 0.27
|
1
2
3
4
5
6
7
8
9
10
|
# mpstat查看CPU使用情况 -P ALL 表示监控所有CPU,后面数字5表示间隔5秒后输出一组数据
[root@test-monitor-alert-1 ~]# mpstat -P ALL 5
Linux 3.10.0-1127.19.1.el7.x86_64 (test-monitor-alert-1) 11/24/2020 _x86_64_ (4 CPU)
08:45:14 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
08:45:19 PM all 0.75 0.00 1.86 89.53 0.00 0.00 0.00 0.00 0.00 7.85
08:45:19 PM 0 0.61 0.00 2.42 91.92 0.00 0.00 0.00 0.00 0.00 5.05
08:45:19 PM 1 0.80 0.00 2.20 76.15 0.00 0.00 0.00 0.00 0.00 20.84
08:45:19 PM 2 0.81 0.00 1.21 92.74 0.00 0.00 0.00 0.00 0.00 5.24
08:45:19 PM 3 0.80 0.00 1.41 97.59 0.00 0.00 0.00 0.00 0.00 0.20
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 使用 pidstat 来查询到底是哪个进程导致了iowait这么高
# 间隔5秒后输出一组数据
[root@test-monitor-alert-1 sysstat-11.6.5]# ./pidstat -u 5 1
Linux 3.10.0-1127.19.1.el7.x86_64 (test-monitor-alert-1) 11/25/2020 _x86_64_ (4 CPU)
Average: UID PID %usr %system %guest %wait %CPU CPU Command
Average: 0 275 0.00 0.60 0.00 0.00 0.60 - kworker/0:1H
Average: 0 292 0.00 2.60 0.00 0.00 2.60 - jbd2/vda1-8
Average: 0 1347 0.20 0.20 0.00 0.00 0.40 - dockerd
Average: 0 1472 0.40 0.20 0.00 0.00 0.60 - node_exporter
Average: 0 1598 0.00 0.20 0.00 0.00 0.20 - docker-containe
Average: 1000 2066 1.00 1.40 0.00 0.00 2.40 - java
Average: 0 4950 0.00 0.80 0.00 0.00 0.80 - etcd
Average: 0 5885 0.00 17.00 0.00 0.00 17.00 - stress-ng-hdd
Average: 0 5886 0.00 0.40 0.00 0.00 0.40 - stress-ng-io
Average: 0 5887 0.00 0.20 0.00 0.00 0.20 - stress-ng-io
Average: 0 8118 0.20 0.00 0.00 0.00 0.20 - java
Average: 0 8449 0.00 1.80 0.00 0.20 1.80 - kworker/u8:0
Average: 0 8458 0.20 0.20 0.00 0.00 0.40 - java
Average: 0 17111 0.00 0.20 0.00 0.20 0.20 - kworker/3:0
Average: 0 26173 0.00 0.20 0.00 0.00 0.20 - notify
Average: 0 26236 0.00 0.20 0.00 0.00 0.20 - barad_agent
Average: 0 28985 0.00 1.60 0.00 0.00 1.60 - YDEdr
|
大量进程
当系统中运行进程超出 CPU 运行能力时,就会出现等待 CPU 的进程。
1
2
3
4
|
# 测试之前的数据
[root@test-monitor-alert-1 ~]# uptime
09:44:17 up 27 days, 16:28, 4 users, load average: 0.02, 1.90, 2.54
|
1
2
3
|
# 模拟多进程
[root@test-monitor-alert-1 ~]# stress -c 8 --timeout 600
stress: info: [9683] dispatching hogs: 8 cpu, 0 io, 0 vm, 0 hdd
|
1
2
3
4
5
6
|
# uptime查看平均负载变化情况
# 由于系统只有 4 个 CPU,明显比 8 个进程要少得多,因而,系统的 CPU 处于严重过载状态,平均负载高达 8.08
[root@test-monitor-alert-1 ~]# watch -d uptime
Every 2.0s: uptime Wed Nov 25 09:47:07 2020
09:47:08 up 27 days, 16:31, 4 users, load average: 8.08, 3.72, 3.05
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# 使用 pidstat 来看一下进程的情况
# 间隔5秒后输出一组数据
[root@test-monitor-alert-1 sysstat-11.6.5]# ./pidstat -u 5 1
Linux 3.10.0-1127.19.1.el7.x86_64 (test-monitor-alert-1) 11/25/2020 _x86_64_ (4 CPU)
09:47:44 AM UID PID %usr %system %guest %wait %CPU CPU Command
09:47:49 AM 1000 2066 1.59 0.20 0.00 0.00 1.79 0 java
09:47:49 AM 65534 2525 0.20 0.00 0.00 0.00 0.20 1 prometheus
09:47:49 AM 0 4950 0.20 0.20 0.00 1.39 0.40 2 etcd
09:47:49 AM 0 8118 0.00 0.20 0.00 0.00 0.20 0 java
09:47:49 AM 0 8458 0.20 0.00 0.00 0.00 0.20 1 java
09:47:49 AM 0 9290 0.20 0.00 0.00 0.20 0.20 3 watch
09:47:49 AM 0 9684 64.94 0.00 0.00 34.66 64.94 2 stress
09:47:49 AM 0 9685 40.24 0.00 0.00 59.56 40.24 1 stress
09:47:49 AM 0 9686 44.02 0.00 0.00 55.58 44.02 2 stress
09:47:49 AM 0 9687 46.81 0.00 0.00 52.79 46.81 0 stress
09:47:49 AM 0 9688 41.43 0.00 0.00 58.37 41.43 1 stress
09:47:49 AM 0 9689 49.00 0.00 0.00 50.20 49.00 0 stress
09:47:49 AM 0 9690 55.58 0.00 0.00 44.42 55.58 3 stress
09:47:49 AM 0 9691 52.59 0.00 0.00 47.41 52.59 2 stress
09:47:49 AM 0 26155 0.00 0.20 0.00 0.00 0.20 0 docker-containe
09:47:49 AM 0 26236 0.20 0.20 0.00 0.00 0.40 2 barad_agent
09:47:49 AM 999 28742 0.20 0.00 0.00 0.00 0.20 1 mysqld
# 可以看出,8 个进程在争抢 4 个 CPU,每个进程等待 CPU 的时间(也就是代码块中的 %wait 列)高达 50%。这些超出 CPU 计算能力的进程,最终导致 CPU 过载。
|
平均负载高有可能是 CPU 密集型进程导致的;
平均负载高并不一定代表 CPU 使用率高,还有可能是 I/O 更繁忙了;
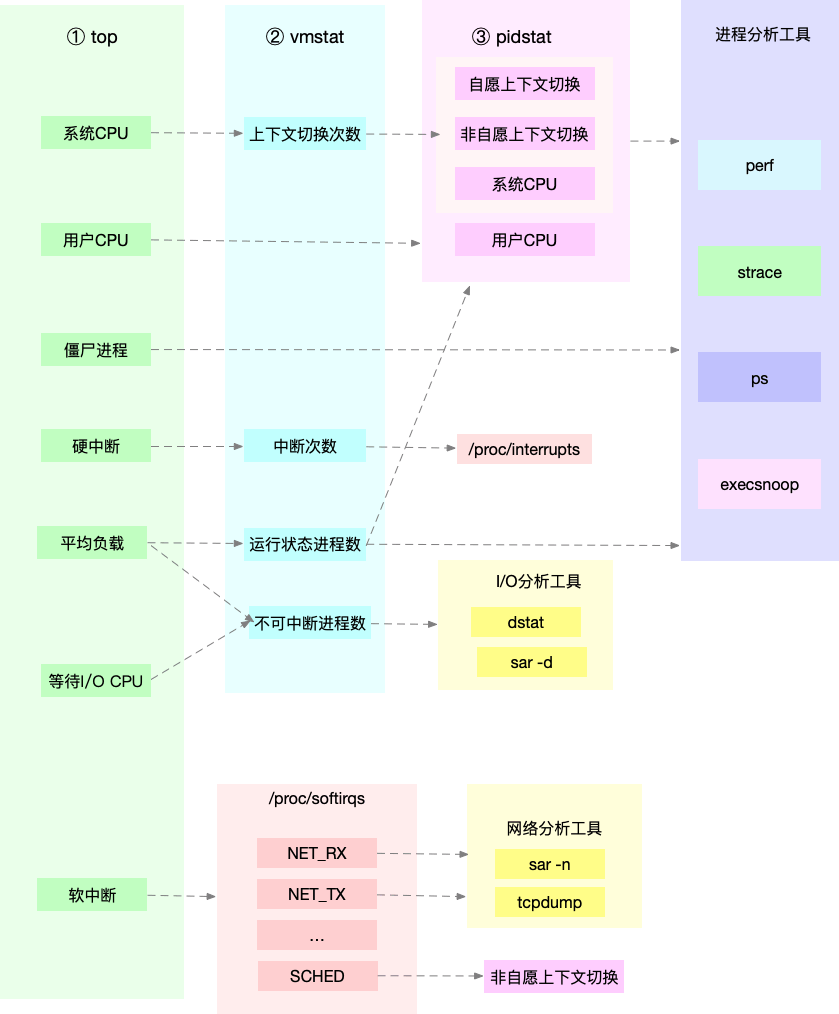
当发现负载高的时候,可以使用 mpstat、pidstat 等工具,辅助分析负载的来源
CPU寄存器、程序计数器:CPU上下文
CPU寄存器是CPU中内置的容量小、速度极快的内存。
程序计数器用来存储CPU正在执行的指令位置、或者即将执行的下一条指令的位置。他们都是CPU在运行任何任务前必须依赖的环境,因此也可以称作CPU上下文。
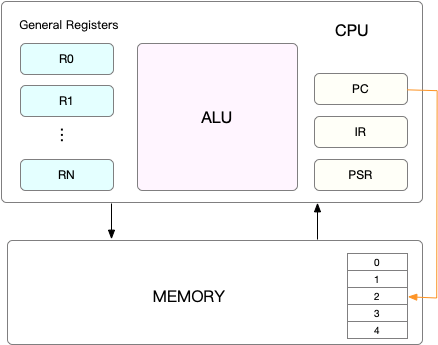
CPU上下文切换
进程在竞争CPU的时候并未真正运行,导致系统负载过高的原因就是CPU上下文切换。
Linux 是一个多任务操作系统,它支持远大于 CPU 数量的任务同时运行。当然,这些任务实际上并不是真的在同时运行,而是因为系统在很短的时间内,将 CPU 轮流分配给它们,造成多任务同时运行的错觉。
在任务运行前CPU都需要知道任务从哪里加载、从哪里运行,简单来说CPU需要系统事先帮它设置好CPU寄存器和程序计数器。
CPU上下文切换就是包前一个任务的CPU上下文保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,然后跳转到程序计数器所指的新位置运行新任务。
进程上下文切换
Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间,分别对应着下图中, CPU 特权等级的 Ring 0 和 Ring 3。如图:
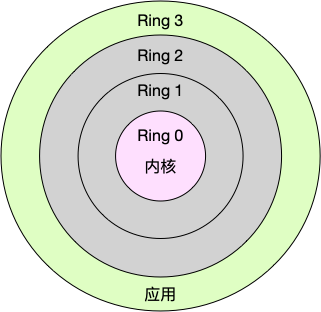
- 内核空间(Ring 0)具有最高权限,可以直接访问所有资源;
- 用户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
进程既可以在用户空间(用户态)运行又可以在内核(内核态)空间运行。进程从用户态到内核态到转变需要通过系统调用来完成。
在系统调用到过程中CPU发生了上下文切换。
CPU 寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU 寄存器需要更新为内核态指令的新位置。最后才是跳转到内核态运行内核任务。而系统调用结束后,CPU 寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程。所以,一次系统调用的过程,其实是发生了两次 CPU 上下文切换。
系统调用过程中,并不涉及虚拟内存等进程用户态的资源,也不会切换进程。所以这里的切换和进程切换是有区别的:
1. 进程上下文切换是从一个进程切换到另一个进程
2. 系统调用过程中,始终在同一个进程在运行。
所以系统调用是一种特权模式的切换。
进程调度和系统调用区别
进程由内核管理和调度的,所以进程切换是发生在内核态的。进程的上下文不仅包括了内存、堆栈等,还包含了内核堆栈、寄存器等内核空的状态。
所以进程上下文切换比系统调用多了一步,在保存当前进程的内核状态和 CPU 寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。 如图:

什么时候会进行上下文切换
- 进程时间片耗尽就会被系统挂起,切换到其它等待进程(为了保证进程公平调度,CPU的时间被划分为一段段时间片,轮流分配给各个进程)
- 进程资源不足时,要等到资源满足才可以运行,这个时候进程也会被挂起
- 进程通过睡眠函数sleep将自己挂起时,也会发生调度
- 有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程可能被挂起
- 发生硬件中断的时候,CPU上的进程也会被挂起,来执行内核中断服务
进程切换的时候会发生上下文恰换,Linux为每个CPU都维护了一个就绪队列,将活跃进程按照优先级和等待CPU的时间排序,选择最需要CPU的进程,也就是优先级和等待CPU时间最长的进程来运行。下面整理来几种进程切换的场景:
线程上下文切换
线程是调度的基本单位,而进程则是资源拥有的基本单位。内核的任务调度实际上是对线程的调度,进程只是为线程提供了虚拟内存、全局变量等资源。
- 当进程只有一个线程的时候,进程对于线程
- 当进程拥有多个线程时,共享虚拟内存、全局变量等资源,这些数据在上下文切换时不需保存
- 多个线程各自拥有自己的私有数据,上下文切换时时需要保存的
中断上下文切换
中断是为了快速响应硬件的事件,中断的优先级比进程高,对被打断对进程来说,需要将当前状态保存下来,以便之后进程恢复运行。
和进程上下文不同,中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括CPU寄存器、内核堆栈、硬件中断参数等。
查看系统上下文切换
1
2
3
4
5
6
7
|
# 每隔5秒输出1组数据
[root@test-tke-node-k21 ~]# vmstat 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 1 0 16538480 238900 12508012 0 0 5 166 0 0 6 6 88 0 0
0 0 0 16540000 238900 12508004 0 0 0 258 11200 18214 6 2 92 0 0
0 0 0 16542944 238900 12508124 0 0 0 273 11778 19454 7 2 92 0 0
|
- cs(context switch)是每秒上下文切换的次数
- in(interrupt)则是每秒中断的次数
- r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待 CPU 的进程数
- b(Blocked)则是处于不可中断睡眠状态的进程数
Procs(进程):
- r: 运行队列中进程数量
- b: 等待IO的进程数量
Memory(内存):
- swpd: 使用虚拟内存大小
- free: 可用内存大小
- buff: 用作缓冲的内存大小
- cache: 用作缓存的内存大小
Swap:
- si: 每秒从交换区写到内存的大小
- so: 每秒写入交换区的内存大小
IO:(现在的Linux版本块的大小为1024bytes)
系统:
- in: 每秒中断数,包括时钟中断。【interrupt】
- cs: 每秒上下文切换数。 【count/second】
CPU(以百分比表示):
- us: 用户进程执行时间(user time)
- sy: 系统进程执行时间(system time)
- id: 空闲时间(包括IO等待时间),中央处理器的空闲时间 。以百分比表示。
- wa: 等待IO时间
查看每个进程上下文切换的情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 每隔5秒输出1组数据
[root@test-tke-node-k21 ~]# pidstat -w 5
Linux 4.14.105-19-0012 (test-tke-node-k21) 11/30/2020 _x86_64_ (16 CPU)
08:26:23 PM UID PID cswch/s nvcswch/s Command
08:26:28 PM 0 1 1.39 0.00 systemd
08:26:28 PM 0 408 2.39 0.00 jbd2/vda1-8
08:26:28 PM 0 821 1.00 0.00 auditd
08:26:28 PM 81 851 2.19 0.00 dbus-daemon
08:26:28 PM 0 854 81.67 0.00 systemd-logind
08:26:28 PM 0 2603 17.73 0.00 xfsaild/vdb
08:26:28 PM 0 5856 0.40 0.00 ip-masq-agent
08:26:28 PM 0 176333 0.20 0.00 docker-containe
08:26:28 PM 99 247899 1.39 0.00 dnsmasq
08:26:28 PM 1000 818340 1.79 0.00 php-fpm
08:26:28 PM 1000 818678 0.20 0.00 php-fpm
08:26:28 PM 0 879677 1.99 0.00 wukong-go
08:26:28 PM 0 879734 0.40 0.00 wukong-go
08:26:28 PM 0 1133084 0.20 0.00 docker-containe
08:26:28 PM 0 1322604 79.68 4.58 kube-proxy
08:26:28 PM 0 1396221 0.20 0.00 log-collector
08:26:28 PM 0 1396237 1.99 0.00 fluentd
08:26:28 PM 0 1396247 3.19 0.00 ruby
|
- cswch表示每秒自愿上下文切换(voluntary context switches)的次数(自愿上下文切换,指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换。(当某一任务处于阻塞等待时等等))
- nvcswch表示每秒非自愿上下文切换(non voluntary context switches)的次数(非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换)
例子
1
2
3
4
5
|
# 间隔1秒后输出1组数据
[root@test-tke-node-k21 ~]# vmstat 1 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 16466196 238908 12583356 0 0 5 166 0 0 6 6 88 0 0
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# 以10个线程运行5分钟的基准测试,模拟多线程切换的问题
[root@test-tke-node-k21 ~]# sysbench --threads=10 --max-time=300 threads run
WARNING: --max-time is deprecated, use --time instead
sysbench 1.0.17 (using system LuaJIT 2.0.4)
Running the test with following options:
Number of threads: 10
Initializing random number generator from current time
Initializing worker threads...
Threads started!
|
1
2
3
4
5
6
7
8
9
10
11
12
|
[root@test-tke-node-k21 ~]# vmstat 1
# 每隔1秒输出1组数据
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
14 0 0 16321480 239636 12712368 0 0 5 166 0 0 6 6 88 0 0
9 0 0 16322324 239636 12712316 0 0 0 0 180878 783183 16 36 48 0 0
10 0 0 16322848 239636 12712316 0 0 0 524 95575 820357 16 35 49 0 0
10 0 0 16322512 239636 12712500 0 0 0 488 101780 821691 14 37 49 0 0
12 0 0 16322304 239636 12712332 0 0 0 116 118060 804412 20 36 44 0 0
9 0 0 16322612 239636 12712408 0 0 0 0 159525 754018 22 36 42 0 0
11 0 0 16307728 239636 12712464 0 0 0 524 88452 829684 15 36 49 0 0
8 0 0 16324056 239636 12712364 0 0 0 0 96059 826541 15 36 49 0 0
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
|
# 每隔1秒输出1组数据(需要 Ctrl+C 才结束)
# -w参数表示输出进程切换指标,而-u参数则表示输出CPU使用指标
[root@test-tke-node-k21 ~]# pidstat -w -u 1
Linux 4.14.105-19-0012 (test-tke-node-k21) 11/30/2020 _x86_64_ (16 CPU)
09:04:51 PM UID PID %usr %system %guest %CPU CPU Command
09:04:52 PM 0 1 0.00 0.98 0.00 0.98 15 systemd
09:04:52 PM 0 854 0.98 0.00 0.00 0.98 6 systemd-logind
09:04:52 PM 0 3475 1.96 0.00 0.00 1.96 8 dockerd
09:04:52 PM 0 3488 0.00 0.98 0.00 0.98 14 docker-containe
09:04:52 PM 0 3581 2.94 0.00 0.00 2.94 6 kubelet
09:04:52 PM 0 153780 100.00 100.00 0.00 100.00 11 sysbench
09:04:52 PM 0 154330 0.00 1.96 0.00 1.96 7 pidstat
09:04:52 PM 0 1741126 0.00 0.98 0.00 0.98 9 wukong-go
09:04:52 PM 0 1847481 0.98 0.00 0.00 0.98 7 wukong-go
09:04:52 PM 0 1968378 0.98 0.00 0.00 0.98 8 wukong-go
09:04:52 PM 0 2035882 0.98 0.00 0.00 0.98 7 YDEdr
09:04:52 PM 0 2245987 0.00 0.98 0.00 0.98 10 wukong-go
09:04:52 PM 0 2491812 0.98 0.00 0.00 0.98 7 barad_agent
09:04:52 PM 0 2726307 0.98 0.00 0.00 0.98 1 wukong-go
09:04:52 PM 0 2726406 0.00 0.98 0.00 0.98 9 docker-containe
09:04:52 PM 0 3205475 5.88 0.00 0.00 5.88 9 wukong-go
09:04:51 PM UID PID cswch/s nvcswch/s Command
09:04:52 PM 0 1 1.96 0.00 systemd
09:04:52 PM 0 7 6.86 0.00 ksoftirqd/0
09:04:52 PM 0 8 128.43 0.00 rcu_sched
09:04:52 PM 0 10 0.98 0.00 migration/0
09:04:52 PM 0 11 0.98 0.00 watchdog/0
09:04:52 PM 0 14 0.98 0.00 watchdog/1
09:04:52 PM 0 16 2.94 0.00 ksoftirqd/1
09:04:52 PM 0 20 0.98 0.00 watchdog/2
09:04:52 PM 0 22 0.98 0.00 ksoftirqd/2
09:04:52 PM 0 26 0.98 0.00 watchdog/3
09:04:52 PM 0 28 0.98 0.00 ksoftirqd/3
09:04:52 PM 0 32 0.98 0.00 watchdog/4
09:04:52 PM 0 33 0.98 0.00 migration/4
09:04:52 PM 0 38 0.98 0.00 watchdog/5
09:04:52 PM 0 44 0.98 0.00 watchdog/6
09:04:52 PM 0 46 0.98 0.00 ksoftirqd/6
09:04:52 PM 0 50 0.98 0.00 watchdog/7
09:04:52 PM 0 56 0.98 0.00 watchdog/8
09:04:52 PM 0 58 0.98 0.00 ksoftirqd/8
09:04:52 PM 0 64 0.98 0.00 ksoftirqd/9
09:04:52 PM 0 70 0.98 0.00 ksoftirqd/10
09:04:52 PM 0 76 1.96 0.00 ksoftirqd/11
09:04:52 PM 0 88 11.76 0.00 ksoftirqd/13
09:04:52 PM 0 94 14.71 0.00 ksoftirqd/14
09:04:52 PM 0 100 4.90 0.00 ksoftirqd/15
09:04:52 PM 998 846 0.98 0.00 lsmd
09:04:52 PM 81 851 1.96 0.00 dbus-daemon
09:04:52 PM 0 854 82.35 0.00 systemd-logind
09:04:52 PM 0 2603 17.65 0.00 xfsaild/vdb
09:04:52 PM 0 5856 0.98 0.00 ip-masq-agent
09:04:52 PM 0 40848 1.96 0.00 kworker/9:0
09:04:52 PM 0 54827 3.92 0.00 kworker/8:3
09:04:52 PM 0 63763 1.96 0.00 kworker/13:1
09:04:52 PM 0 77632 1.96 0.00 kworker/2:0
09:04:52 PM 0 90968 4.90 0.00 kworker/11:2
09:04:52 PM 0 95640 1.96 0.00 kworker/4:1
09:04:52 PM 0 109150 0.98 0.00 kworker/6:1
09:04:52 PM 0 109261 2.94 0.00 kworker/12:1
09:04:52 PM 0 113800 3.92 0.00 kworker/5:3
09:04:52 PM 0 116666 2.94 0.00 kworker/1:0
09:04:52 PM 0 125144 9.80 0.00 kworker/3:1
09:04:52 PM 0 127807 4.90 0.00 kworker/7:0
09:04:52 PM 0 132114 8.82 0.00 kworker/0:1
09:04:52 PM 0 141303 6.86 0.00 kworker/15:0
09:04:52 PM 89 146085 0.98 0.00 trivial-rewrite
09:04:52 PM 0 146091 1.96 0.00 kworker/14:0
09:04:52 PM 0 149169 8.82 0.00 kworker/10:1
09:04:52 PM 0 154330 0.98 0.00 pidstat
09:04:52 PM 99 247899 1.96 0.00 dnsmasq
09:04:52 PM 1000 818340 0.98 0.00 php-fpm
09:04:52 PM 0 1396237 1.96 0.00 fluentd
09:04:52 PM 0 1396247 2.94 0.00 ruby
09:04:52 PM 0 2035882 0.98 0.00 YDEdr
09:04:52 PM 0 2491811 2.94 0.00 barad_agent
09:04:52 PM 0 2522357 4.90 0.00 wukong-go
09:04:52 PM 0 2726406 0.98 0.00 docker-containe
# -wt 参数表示输出线程的上下文切换指标
[root@test-tke-node-k21 ~]# pidstat -wt -u 1 | grep sysbench
[root@test-tke-node-k21 ~]# pidstat -wt -u 1
Linux 4.14.105-19-0012 (test-tke-node-k21) 11/30/2020 _x86_64_ (16 CPU)
10:31:49 PM UID TGID TID %usr %system %guest %CPU CPU Command
10:31:50 PM 0 1 - 0.90 0.00 0.00 0.90 1 systemd
10:31:50 PM 0 548753 - 100.00 100.00 0.00 100.00 11 sysbench
10:31:50 PM 0 - 548754 27.03 64.86 0.00 91.89 10 |__sysbench
10:31:50 PM 0 - 548755 27.93 63.96 0.00 91.89 5 |__sysbench
10:31:50 PM 0 - 548756 32.43 60.36 0.00 92.79 2 |__sysbench
10:31:50 PM 0 - 548757 23.42 68.47 0.00 91.89 11 |__sysbench
10:31:50 PM 0 - 548758 25.23 67.57 0.00 92.79 6 |__sysbench
10:31:50 PM 0 - 548759 24.32 67.57 0.00 91.89 7 |__sysbench
10:31:50 PM 0 - 548760 24.32 67.57 0.00 91.89 13 |__sysbench
10:31:50 PM 0 - 548761 27.03 65.77 0.00 92.79 4 |__sysbench
10:31:50 PM 0 - 548762 23.42 68.47 0.00 91.89 12 |__sysbench
10:31:50 PM 0 - 548763 25.23 65.77 0.00 90.99 3 |__sysbench
Average: UID TGID TID cswch/s nvcswch/s Command
Average: 0 - 548754 37902.70 15.32 |__sysbench
Average: 0 - 548755 39209.01 27.93 |__sysbench
Average: 0 - 548756 38840.54 26.13 |__sysbench
Average: 0 - 548757 41057.66 8.11 |__sysbench
Average: 0 - 548758 38201.80 15.32 |__sysbench
Average: 0 - 548759 41139.64 6.31 |__sysbench
Average: 0 - 548760 37354.05 69.37 |__sysbench
Average: 0 - 548761 39441.44 17.12 |__sysbench
Average: 0 - 548762 38177.48 28.83 |__sysbench
Average: 0 - 548763 41107.21 40.54 |__sysbench
Average: 0 549036 - 0.90 1.80 pidstat
# ....
|
1
2
3
4
5
6
7
|
# 观察中断的变化情况
[root@test-tke-node-k21 ~]# watch -d cat /proc/interrupts
# cat /proc/interrupts
# 从左至右:中断号 中断次数 中断设备名称
# 如下图
# ...
|
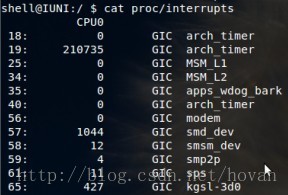
重调度中断(RES),这个中断类型表示,唤醒空闲状态的 CPU 来调度新的任务运行。这是多处理器系统(SMP)中,调度器用来分散任务到不同 CPU 的机制,通常也被称为处理器间中断(Inter-Processor Interrupts,IPI)。
- 自愿上下文切换变多了,说明进程都在等待资源,有可能发生了 I/O 等其他问题
- 非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢 CPU,说明 CPU 的确成了瓶颈
- 中断次数变多了,说明 CPU 被中断处理程序占用,还需要通过查看 /proc/interrupts 文件来分析具体的中断类型。
CPU 100%之后该怎么办
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数
[root@test-tke-node-k21 ~]# perf top
# perf top -g 开启调用关系的采样,方便根据调用链来分析性能问题
Samples: 157K of event 'cpu-clock', Event count (approx.): 35995554317
Overhead Shared Object Symbol ◆
18.11% [kernel] [k] _raw_spin_unlock_irqrestore ▒
14.61% [kernel] [k] __sched_text_start ▒
12.29% [kernel] [k] do_syscall_64 ▒
9.64% libc-2.17.so [.] __sched_yield ▒
7.43% libpthread-2.17.so [.] pthread_mutex_unlock ▒
7.34% [kernel] [k] finish_task_switch ▒
2.41% libpthread-2.17.so [.] pthread_mutex_lock ▒
1.64% [kernel] [k] tick_nohz_idle_enter ▒
1.41% libpthread-2.17.so [.] __lll_lock_wait ▒
1.32% [kernel] [k] __audit_syscall_exit ▒
1.21% [kernel] [k] __pv_queued_spin_lock_slowpath ▒
0.96% [kernel] [k] tick_nohz_idle_exit ▒
0.91% [kernel] [k] __audit_syscall_entry ▒
0.90% libpthread-2.17.so [.] __lll_unlock_wake ▒
0.67% [kernel] [k] futex_wake ▒
0.65% [kernel] [k] syscall_trace_enter ▒
0.65% kubelet [.] _start ▒
0.65% [kernel] [k] do_idle ▒
|
- Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示
- Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等
- Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间
- Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示
案例分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
|
# 运行测试服务
[root@test-tke-node-k21 ~]# docker run --name nginx -p 10000:80 -itd feisky/nginx
[root@test-tke-node-k21 ~]# docker run --name phpfpm -itd --network container:nginx feisky/php-fpm
[root@test-tke-node-k21 ~]# top
top - 11:07:07 up 127 days, 20:52, 2 users, load average: 1.92, 1.42, 1.55
Tasks: 450 total, 6 running, 318 sleeping, 0 stopped, 0 zombie
%Cpu(s): 41.0 us, 3.6 sy, 0.0 ni, 53.8 id, 0.0 wa, 0.0 hi, 1.6 si, 0.0 st
KiB Mem : 32412656 total, 15455832 free, 3158432 used, 13798392 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 29064108 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1322604 root 20 0 212268 78780 0 S 189.9 0.2 54644:05 kube-proxy
3973285 bin 20 0 336696 16352 8664 R 98.7 0.1 0:08.04 php-fpm
3973319 bin 20 0 336696 13200 5520 R 98.7 0.0 0:07.96 php-fpm
3973320 bin 20 0 336696 13136 5456 R 98.7 0.0 0:07.95 php-fpm
3973321 bin 20 0 336696 13076 5396 R 98.7 0.0 0:07.88 php-fpm
3973322 bin 20 0 336696 13140 5460 R 98.7 0.0 0:07.88 php-fpm
3581 root 20 0 2122004 160940 18672 S 11.4 0.5 7908:01 kubelet
2962155 root 20 0 729632 55472 12772 S 10.1 0.2 102:22.64 wukong-go
3475 root 20 0 2384864 144036 18664 S 3.8 0.4 18601:39 dockerd
2035882 root 20 0 841168 17044 11040 S 2.5 0.1 151:47.57 YDEdr
3971722 root 20 0 12568 6140 1476 S 2.5 0.0 0:00.26 docker-proxy
1 root 20 0 192996 7132 3692 S 1.3 0.0 620:19.81 systemd
# perf 看出 add_function sqrt 消耗比较大
[root@test-tke-node-k21 ~]# perf top -g -p 3973285
Samples: 111K of event 'cpu-clock', Event count (approx.): 14077224392
Overhead Shared Object Symbol ◆
- 5.91% php-fpm [.] add_function ▒
- 5.91% add_function ▒
+ 5.14% 0x98dd97 ▒
- 5.74% libm-2.24.so [.] sqrt ▒
sqrt ▒
0x8c4a7c ▒
execute_ex ▒
zend_execute ▒
zend_execute_scripts ▒
php_execute_script ▒
0x9cb642 ▒
__libc_start_main ▒
0x6cb6258d4c544155 ▒
+ 4.87% php-fpm [.] execute_ex ▒
+ 2.45% php-fpm [.] 0x000000000094ede0 ▒
+ 1.55% php-fpm [.] 0x0000000000681b9d ▒
+ 0.95% php-fpm [.] 0x00000000008cd720 ▒
+ 0.80% php-fpm [.] 0x0000000000681d21 ▒
+ 0.79% php-fpm [.] 0x0000000000681d1a ▒
+ 0.74% php-fpm [.] 0x000000000098dc03
# 导出源码
[root@test-tke-node-k21 ~]# docker cp phpfpm:/app .
[root@test-tke-node-k21 ~]# grep sqrt -r app/
app/index.php: $x += sqrt($x);
# add_function是php内置函数,这里看不到
[root@test-tke-node-k21 ~]# grep add_function -r app/
[root@test-tke-node-k21 ~]# cat app/index.php
<?php
// test only.
$x = 0.0001;
for ($i = 0; $i <= 1000000; $i++) {
$x += sqrt($x);
}
echo "It works!"
# 停止原来的应用
[root@test-tke-node-k21 ~] docker rm -f nginx phpfpm
# 运行优化后的应用
[root@test-tke-node-k21 ~] docker run --name nginx -p 10000:80 -itd feisky/nginx:cpu-fix
[root@test-tke-node-k21 ~] docker run --name phpfpm -itd --network container:nginx feisky/php-fpm:cpu-fix
# 应用里直接调用了其他二进制程序,这些程序通常运行时间比较短,通过 top 等工具也不容易发现
# 应用本身在不停地崩溃重启,而启动过程的资源初始化,很可能会占用相当多的 CPU
# 用下面的方式去排查
# 记录性能事件,等待大约15秒后按 Ctrl+C 退出
[root@test-tke-node-k21 ~] perf record -g
# 查看报告
[root@test-tke-node-k21 ~] perf report
[root@test-tke-node-k21 bin]# dstat 1 10
You did not select any stats, using -cdngy by default.
----total-cpu-usage---- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai hiq siq| read writ| recv send| in out | int csw
6 2 88 0 0 3| 73k 2632k| 0 0 | 0 0 | 11k 35k
0 0 99 0 0 0|4096B 608k| 108k 122k| 0 0 |7080 12k
9 2 89 0 0 0| 0 472k| 111k 128k| 0 0 |8503 13k
5 2 93 0 0 0|4096B 108k| 125k 231k| 0 0 | 10k 16k
1 0 99 0 0 0| 16k 548k| 92k 102k| 0 0 |5700 9569
2 1 97 0 0 0|8192B 0 | 87k 158k| 0 0 | 15k 25k
7 3 90 0 0 0|4096B 0 | 121k 87k| 0 0 | 18k 30kq
15 3 82 0 0 0| 0 656k| 76k 175k| 0 0 | 14k 23k
|
软中断
中断处理程序在响应中断时,还会临时关闭中断。这就会导致上一次中断处理完成之前,其他中断都不能响应,也就是说中断有可能会丢失。
Linux 将中断处理过程分成了两个阶段上半部和下半部,这样做的原因是为了减少对正常进程运行调度的影响,同时中断处理程序需要尽可能快地运行。
- 上半部用来快速处理中断,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作
- 下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行
网卡接收到数据包后,会通过硬件中断的方式,通知内核有新的数据到了。
这时,内核就应该调用中断处理程序来响应它。
- 对上半部来说,其实就是要把网卡的数据读到内存中,然后更新一下硬件寄存器的状态(表示数据已经读好了)
- 最后再发送一个软中断信号,通知下半部做进一步的处理。
- 下半部被软中断信号唤醒后,需要从内存中找到网络数据,再按照网络协议栈,对数据进行逐层解析和处理,直到把它送给应用程序。
总结来说:
- 上半部直接处理硬件请求,也就是硬中断,特点是快速执行
- 下半部则是由内核触发,也就是软中断,特点是延迟执行
实际上,上半部会打断 CPU 正在执行的任务,然后立即执行中断处理程序。而下半部以内核线程的方式执行,并且每个 CPU 都对应一个软中断内核线程,名字为 “ksoftirqd/CPU 编号”,比如说, 0 号 CPU 对应的软中断内核线程的名字就是 ksoftirqd/0。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 软中断内核线程就叫做 ksoftirqd/CPU 编号, 查看方式
[root@test-monitor-farseer-1 ~]# ps aux | grep softirq
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 6 0.0 0.0 0 0 ? S Oct28 19:01 [ksoftirqd/0]
root 14 0.0 0.0 0 0 ? S Oct28 18:35 [ksoftirqd/1]
root 19 0.0 0.0 0 0 ? S Oct28 7:09 [ksoftirqd/2]
root 24 0.0 0.0 0 0 ? S Oct28 7:10 [ksoftirqd/3]
root 30245 0.0 0.0 112816 968 pts/0 S+ 14:39 0:00 grep --color=auto softirq
# 各种类型软中断在不同 CPU 上的累积运行次数
# TIMER(定时中断)、NET_RX(网络接收)、SCHED(内核调度)、RCU(RCU 锁)
[root@test-monitor-farseer-1 ~]# cat /proc/softirqs
CPU0 CPU1 CPU2 CPU3
HI: 0 0 1 0
TIMER: 292014081 279537013 269216764 281696252
NET_TX: 3831 3913 4199 4184
NET_RX: 618581709 594412079 267227921 266352263
BLOCK: 14715145 0 0 0
BLOCK_IOPOLL: 0 0 0 0
TASKLET: 2443 2477 2541 2794
SCHED: 99688071 94729309 93448448 103069610
HRTIMER: 0 0 0 0
RCU: 78026892 73588176 68355387 69822162
|
CPU缓存
CPU缓存是为了解决CPU运算速度与内存读写速度不匹配的矛盾,因为CPU的运算速度要比内存读写速度快很多,这样会使CPU需要等待数据的到来或把数据写入到内存中。
高速缓存控制器是针对数据块,而不是字节进行操作的。高速缓存其实就是一组称之为缓存行(Cache Line)的固定大小的数据块组成的,典型的一行是64字节。
CPU缓存的意义
CPU往往需要重复处理相同的数据、重复执行相同的指令,如果这部分数据、指令能在CPU缓存中找到,CPU就不需要从内存或硬盘中再读取数据、指令,从而减少了整机的响应时间。
CPU缓存的意义满足以下两种局部性原理:
- 时间局部性(Temporal Locality):如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。
- 空间局部性(Spatial Locality):如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。
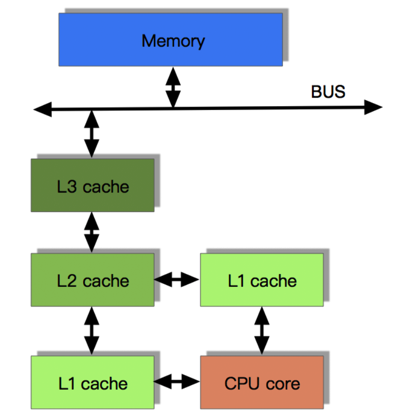
就像数据库缓存一样,获取数据时首先会在最快的缓存中找数据,如果缓存没有命中(Cache miss) 则往下一级找, 直到三级缓存都找不到时,那只有向内存要数据了。一次次地未命中,代表取数据消耗的时间越长。
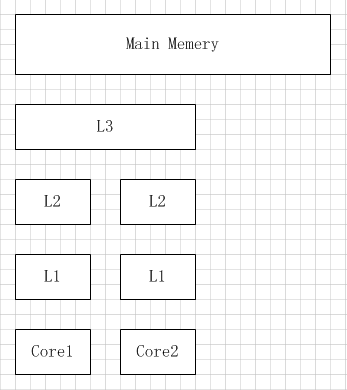
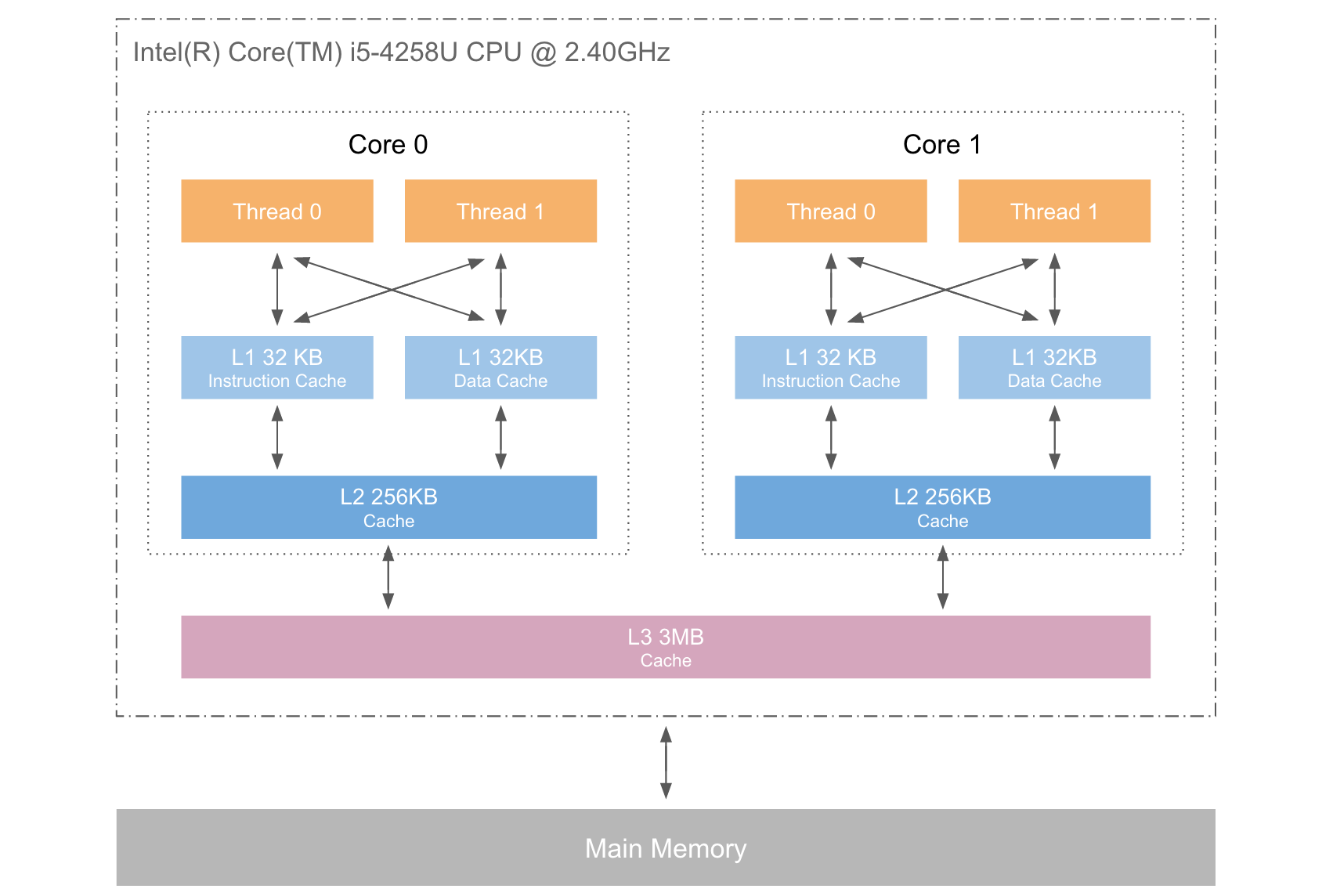
带有高速缓存CPU执行计算的流程
- 程序以及数据被加载到主内存
- 指令和数据被加载到CPU的高速缓存
- CPU执行指令,把结果写到高速缓存
- 高速缓存中的数据写回主内存
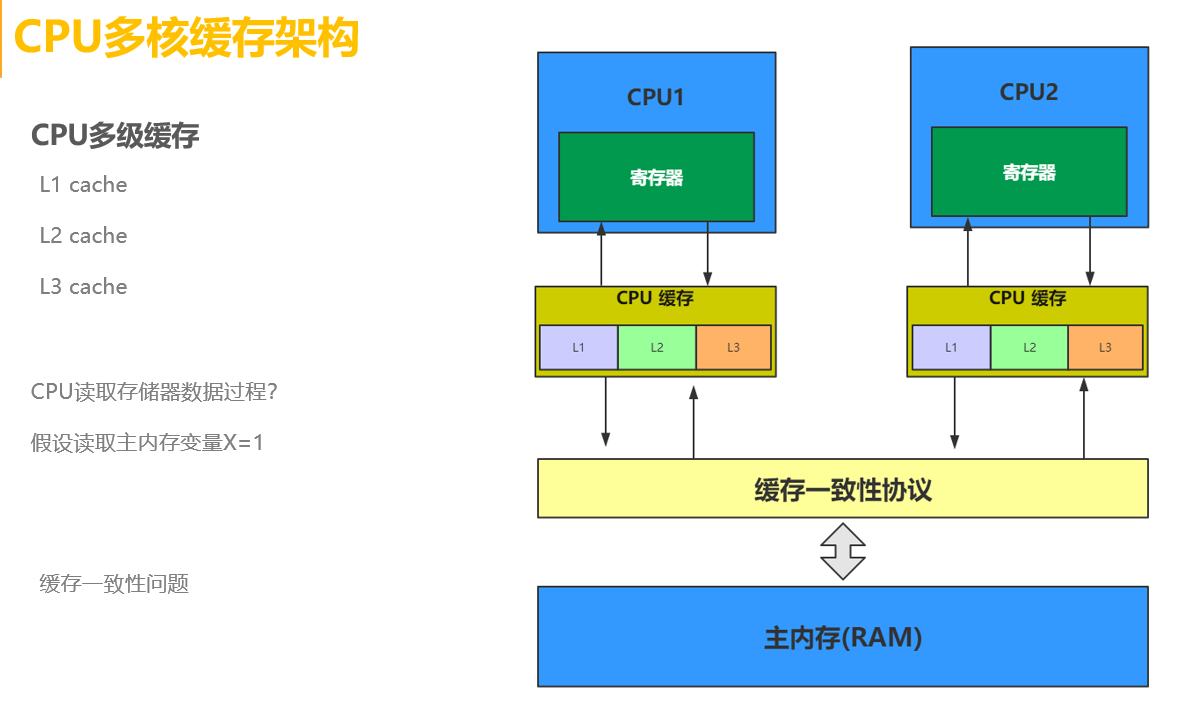
CPU缓存一致性协议-MESI
MESI为了保证多个CPU缓存中共享数据的一致性,为缓存行(Cache Line)定义了四种状态,而CPU对缓存行的四种操作可能会产生不一致的状态,因此缓存控制器监听到本地操作和远程操作的时候,需要对地址一致的缓存行的状态进行一致性修改,从而保证数据在多个缓存之间保持一致性。
MESI状态
| 状态 |
描述 |
监听任务 |
状态转换 |
| M 修改 (Modified) |
该Cache line有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中 |
缓存行必须时刻监听所有试图读该缓存行相对就主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成S(共享)状态之前被延迟执行 |
当被写回主存之后,该缓存行的状态会变成独享(exclusive)状态 |
|
|
|
|
| E 独享、互斥 (Exclusive) |
该Cache line有效,数据和内存中的数据一致,数据只存在于本Cache中 |
缓存行必须监听其它缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成S(共享)状态。 |
当CPU修改该缓存行中内容时,该状态可以变成Modified状态 |
|
|
|
|
| S 共享 (Shared) |
该Cache line有效,数据和内存中的数据一致,数据存在于很多Cache中 |
缓存行必须监听其它缓存使该缓存行无效或者独享该缓存行的请求,并将该缓存行变成无效(Invalid) |
当有一个CPU修改该缓存行时,其它CPU中该缓存行可以被作废(变成无效状态 Invalid) |
|
|
|
|
| I 无效 (Invalid) |
该Cache line无效。 |
无 |
无 |
多核缓存协同操作
内存变量
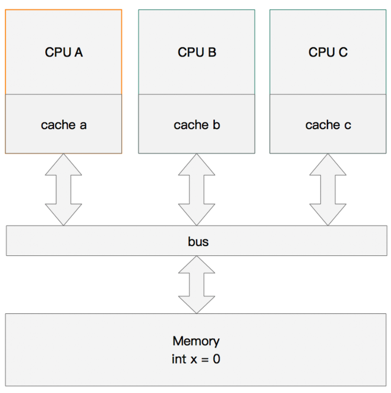
单核读取
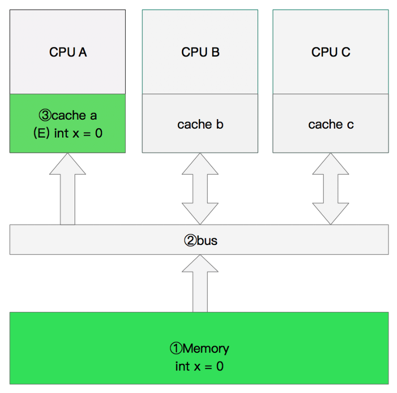
双核读取
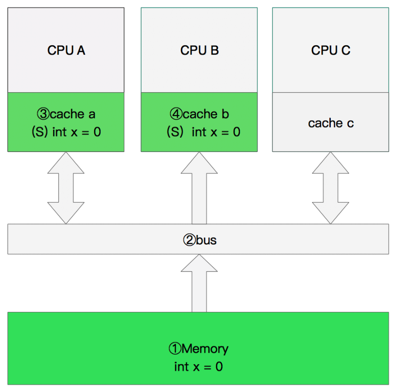
修改数据
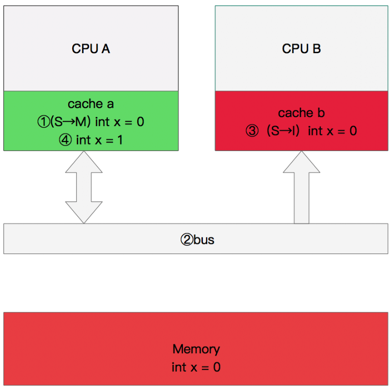
同步数据
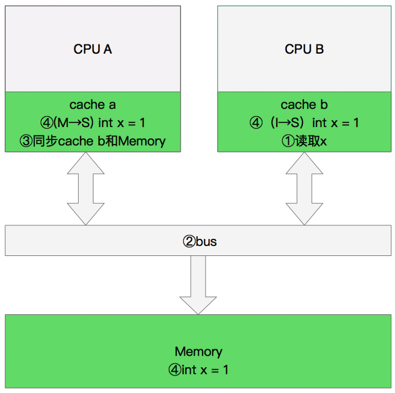
CPU 存储模型简介
MESI协议为了保证多个 CPU cache 中共享数据的一致性,定义了 Cache line 的四种状态,而 CPU 对 cache 的4种操作可能会产生不一致状态,因此 cache 控制器监听到本地操作和远程操作的时候,需要对地址一致的 Cache line 状态做出一定的修改,从而保证数据在多个cache之间流转的一致性。
但是,缓存的一致性消息传递是要时间的,这就使得状态切换会有更多的延迟。某些状态的切换需要特殊的处理,可能会阻塞处理器。这些都将会导致各种各样的稳定性和性能问题。比如你需要修改本地缓存中的一条信息,那么你必须将I(无效)状态通知到其他拥有该缓存数据的CPU缓存中,并且等待确认。等待确认的过程会阻塞处理器,这会降低处理器的性能。因为这个等待远远比一个指令的执行时间长的多。所以,为了为了避免这种阻塞导致时间的浪费,引入了存储缓存(Store Buffer)和无效队列(Invalidate Queue)。